

In this series, I’m focussing on the key differences between Snowflake and BigQuery that have an impact on the data pipeline, table design, performance and costs so it is by no means a detailed product comparison or benchmark.
- Part 1: virtual warehouses, data storage and data loading/unloading
- Part 2: data sharing and multi-cloud capabilities
- Part 3: unstructured data, data masking & data security features and SQL support
Semi-structured data
Relational databases and data warehouses were traditionally used for structured data, basically, anything that fits into rows and columns.
This is not the case with modern cloud data warehouses and the latest versions of relational databases. Support for JSON, XML and data stored in modern files, such as AVRO, Parquet and ORC is available.
This is important because it enables that semi-structured data generated by APIs, web tracking, … can be stored and processed in the cloud data warehouse instead of having to transform the data into a row with a fixed schema. Parsing semi-structured data on the fly is often essential to enable a very fast time to value because fewer code changes, releases and data reloads are needed to support new columns.
BigQuery approaches semi-structured data in 2 ways.
It has native support for nested data structured by providing a record like data type that can be repeated. Using UNNEST and ARRAY_AGG it’s possible to flatten and create nested data structures.

The second approach is storing the JSON data in a STRING column and using the JSON functions, together with UNNEST to extract and manipulate the content. JSONPath is the only support way to retrieve the keys/values.
BigQuery has no out of the box support for XML but simple XML use-case can be solved using JSON user-defined functions.
Snowflake’s platform currently has no support for nested data structures in tables. Semi-structured data is stored and processed in VARIANT, OBJECT and ARRAY data types. These columns are automatically stored in an efficient optimised format. The FLATTEN table function is used to transform the semi-structured data into rows. Compared to UNNEST in BigQuery FLATTEN has more functionality. The RECURSIVE option can be useful in certain use-cases.
Keys and values can be retrieved using Dot or Bracket Notation and casted to the right data type using ::<Snowflake Datatype>. Snowflake has more SQL functions to manipulate arrays and semi-structured data.

Recently Snowflake introduced support for unstructured data, aka files, on distributed storage in private preview with the GET_PRESIGNED_URL(…) function. This function together with UDFs or external functions enables plenty of exciting ML and data integrations options.
SQL Support
As soon as you start working with Snowflake’s platform you notice that it has been designed with SQL in mind. All the functionality, including configuring external functions, integrating with cloud-specific distributed storage, all user admin can be done with SQL. It’s a very familiar environment for people with a background in relational databases or data warehouse appliances.
Snowflake recently introduced a REST API and Snowpark to enable integration using the most common programming languages. This closes the gap with users that have experience with data science and big data processing frameworks.
The number of SQL functions is larger than BigQuery and includes a number of useful extensions such as MATCH_RECOGNIZE to work with patterns in rows and QUALIFY to filter on the output of window functions.
User-defined functions can be written in Javascript, SQL and Java. Snowflake can call external functions, REST APIs, so
Google BigQuery has a wide range of SQL functions. Javascript and SQL user-defined function support is available. In the last 2 years, BigQuery implemented a lot of DDL/DML functionality.
Both solutions have support for GIS analysis
Data masking & data security
Snowflake and BigQuery offer fine-grained security controls.
It’s easy to grant access to databases or datasets, schemas, tables and views.
Row-level data security (Snowflake/BigQuery) is available in both solutions with a similar approach.
Google currently offers column-based security, so access to columns, for example, due to PII data, can be denied for specific users/user groups. This is managed using policy tags in the data catalog. Data masking using policies is currently not available.
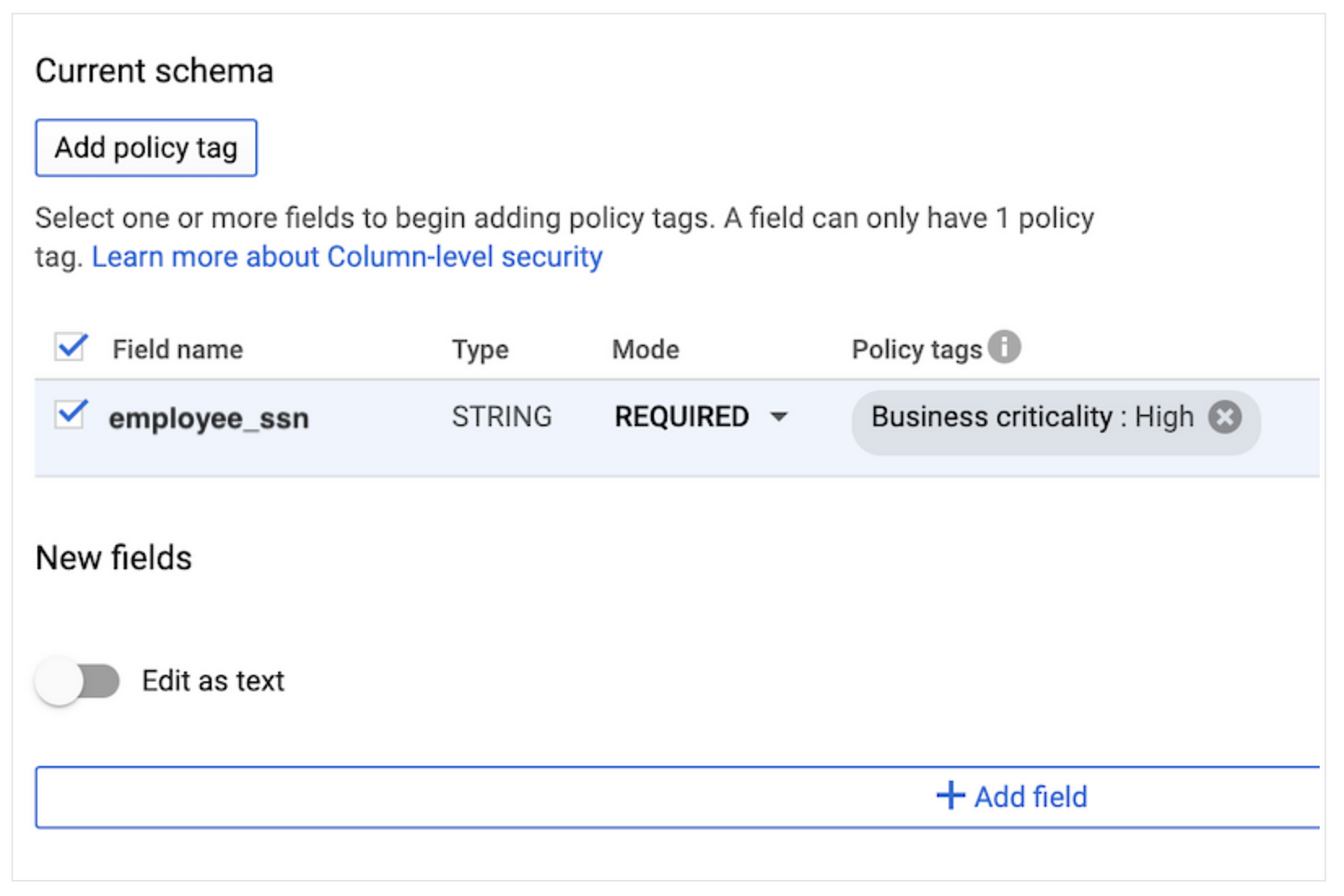
Snowflake’s approach is different. Instead of focussing on access to columns, the data can be hidden by applying role-based data masking or external tokenisation. A masking policy uses SQL so it is possible to mask structured and semi-structured data.

Conclusion — What’s the “best” solution
This is the end of the series. I hope I’ve managed to highlight some of the key differences and similarities between Snowflake and BigQuery.
I guess some of you would like to know what’s the best solution. This is not easy to answer. This depends on your cloud strategy, data strategy, budget, the experience of your team, data volumes, types of data, integration with source systems, integration with data visualisation tools, the need for large scale AI, … Both solutions are excellent fully managed solutions that can support the majority of small and large scale data platform use-cases.
In my opinion, Snowflake is currently ahead of BigQuery because it’s natively designed with multi-cloud deployment and multi-cloud data sharing in mind. Data is essential in modern enterprises and a key ingredient for more advanced ML models, new business models and faster cross-company collaboration. So seamless, secure, no fuss data sharing using Snowflake is and will be a game-changer as soon as people notice they can avoid plenty of additional infrastructures, tools and API layers while maintaining security and audibility.

Snowflake is a great fit for teams with a background in “ old skool” data warehouse appliances and modern data teams that want to run data transformations and analytics in the data layer instead of relying on distributed storage and distributed data processing frameworks.
In certain environments, I wouldn’t mind that Snowflake and BigQuery coexist. It would make absolute sense to keep detailed Google Analytics data in BigQuery and sync aggregates to Snowflake to combine the data with a bunch of CRM/ERP and other data sources.
In a data mesh architecture domains can run on different services as long as the data is accessible, quality controlled and documented. Modern data tools tend to support both platforms.
Get in touch if you have any questions or suggestions! At Tropos.io, as a Snowflake partner, we can help your team with designing a cost-efficient, secure and flexible data pipeline.






